
Transformer源码解读
Transformer源码解读
- About
- 模型总体架构
- 超参数
- 张量维度转换
- 可训练参数量
- 源码
1. About
论文:Attention Is All You Need
年份:2017
公司:Google
源码(哈佛NLP团队实现的Pytorch版):https://github.com/harvardnlp/annotated-transformer/
配套源码解析: https://nlp.seas.harvard.edu/annotated-transformer/
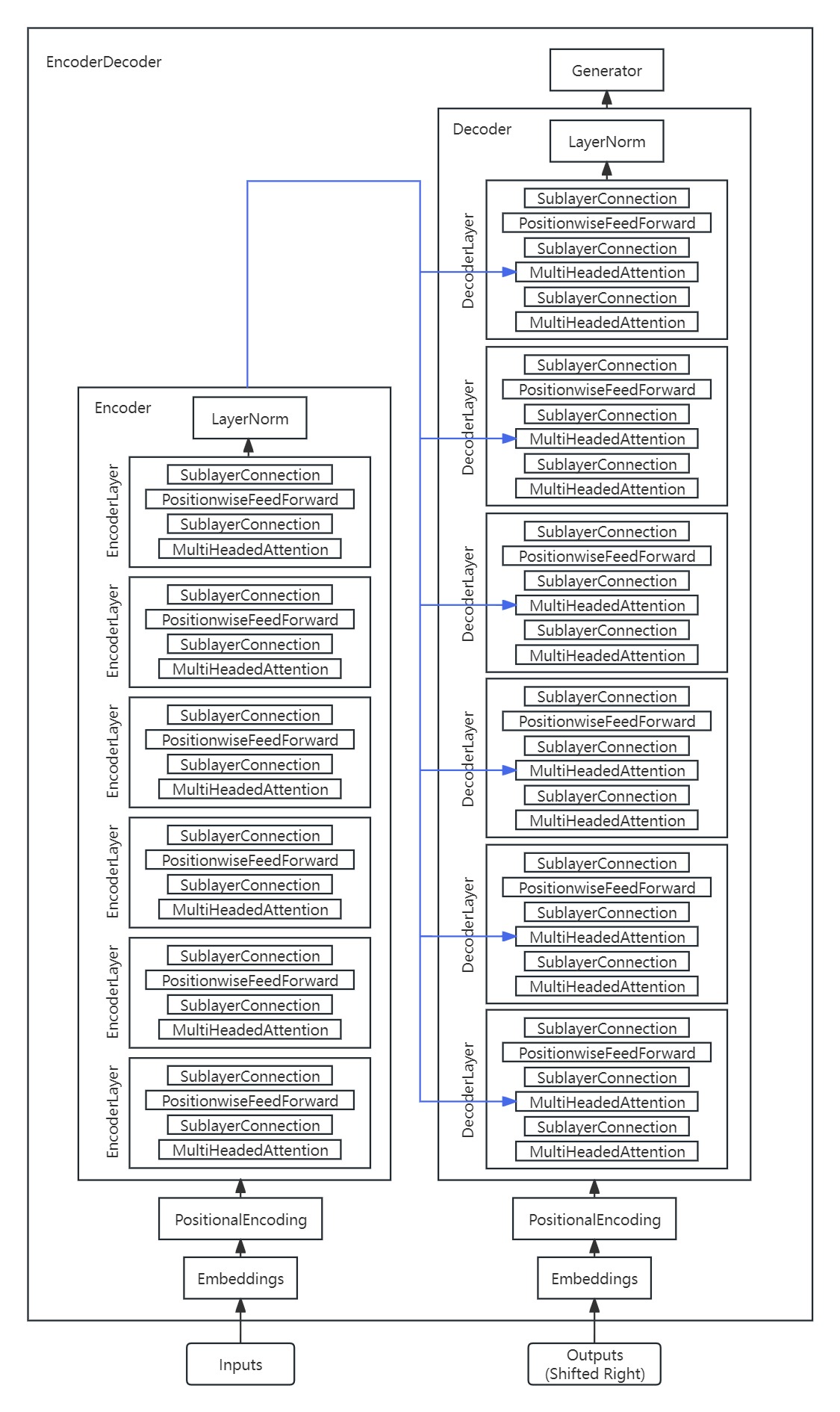
2. 模型总体架构
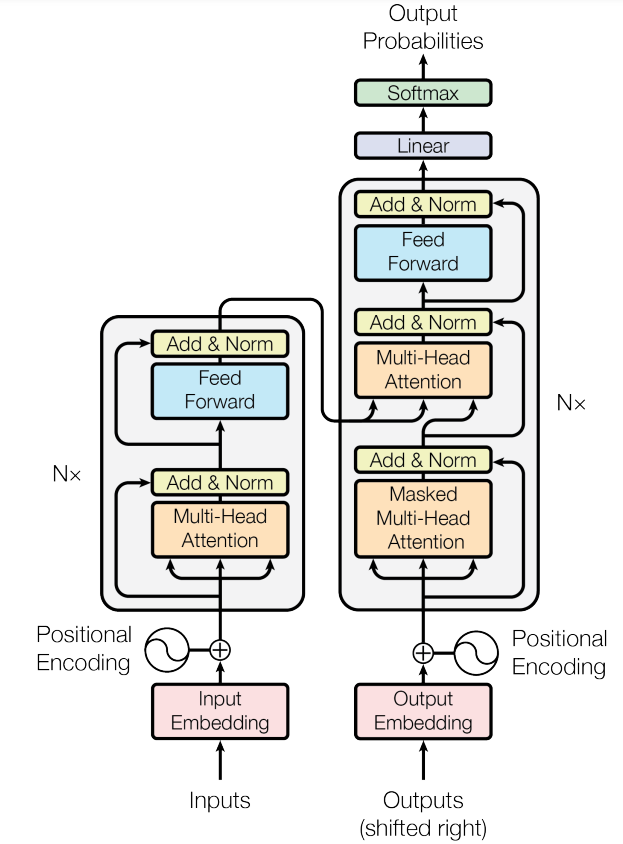
编码器(左侧部分):"Inputs"这是编码器的输入,比如说你中文翻英文的话,那么这就是你中文的句子。编码器将输入序列(x1,...,xn)映射为一系列向量表示 z =(z1,...,zn)。其中每个xt表示输入序列中的第t个元素(例如,一个单词),每个zt是相对于xt的向量表示。这些向量表示可以被视为输入序列的抽象表示,使得机器学习模型能够更好地理解输入序列。
解码器(右侧部分):"Outputs"这是解码器的输入,解码器在做预测的时候是没有输入的。"Shifted Right"就是一个一个往右移。解码器根据编码器的输出进行工作,对z中的每个元素,生成目标序列(y1,...,ym),一个时间步生成一个元素,其中m可能与n不同。在每一步中,模型都是自回归的,在生成下一个结果时,会将先前生成的结果加入输入序列来一起预测。(自回归模型的特点)
解码器与编码器的一个重要区别是,解码器是自回归的(auto-regressive)。这意味着它逐步生成输出序列,而不是一次性处理整个序列。在生成第一个输出y1之后,解码器使用先前生成的输出作为输入来生成下一个输出,以此类推,直到生成完整的目标序列。
总结来说,编码器将输入序列转换为一系列向量表示,而解码器根据编码器的输出逐步生成目标序列。解码器的自回归特性使得它能够逐步生成输出,并利用先前生成的输出作为输入。这种编码器-解码器架构在序列到序列任务中被广泛应用,如机器翻译、摘要生成等。
3. 超参数
4. 张量维度转换
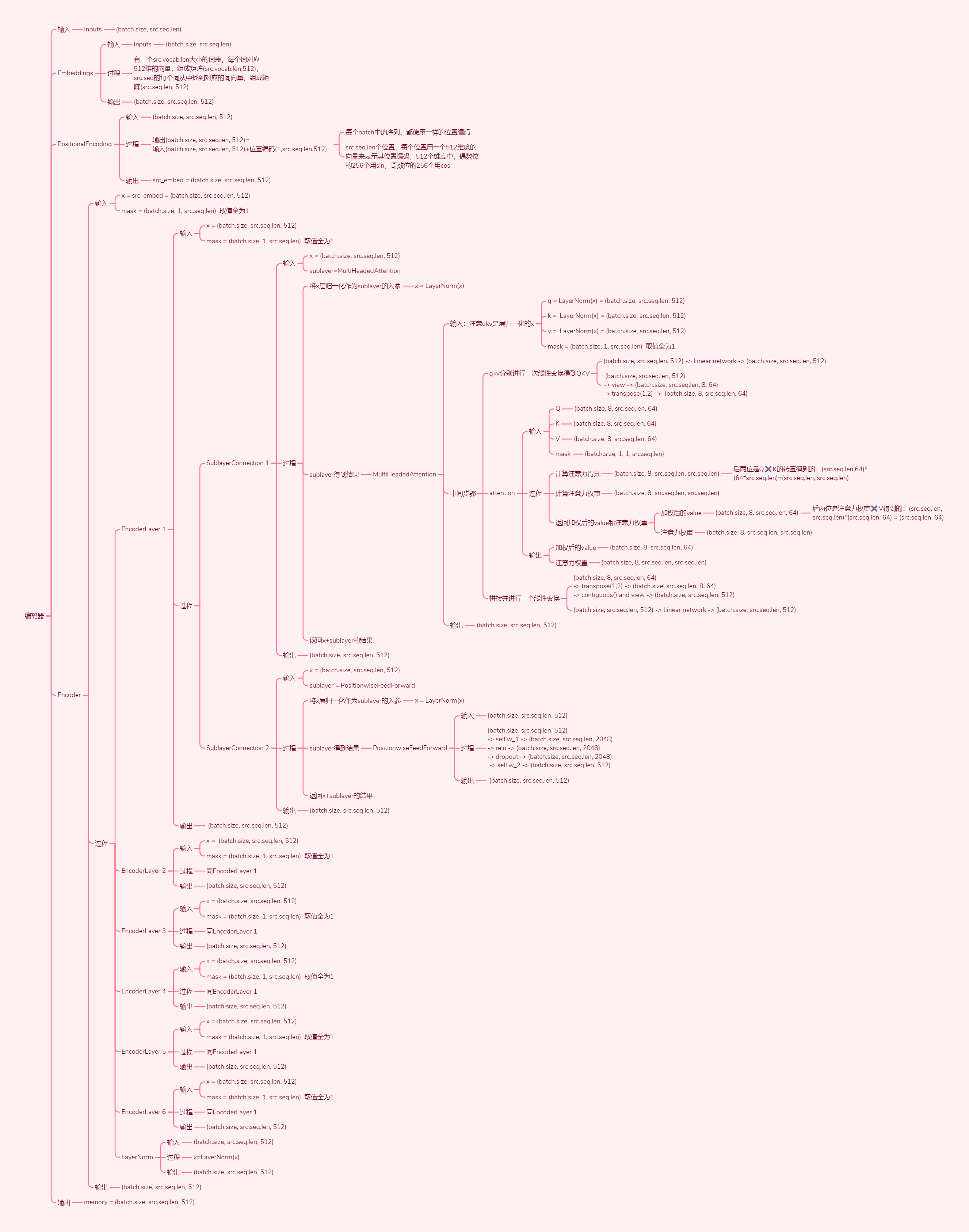
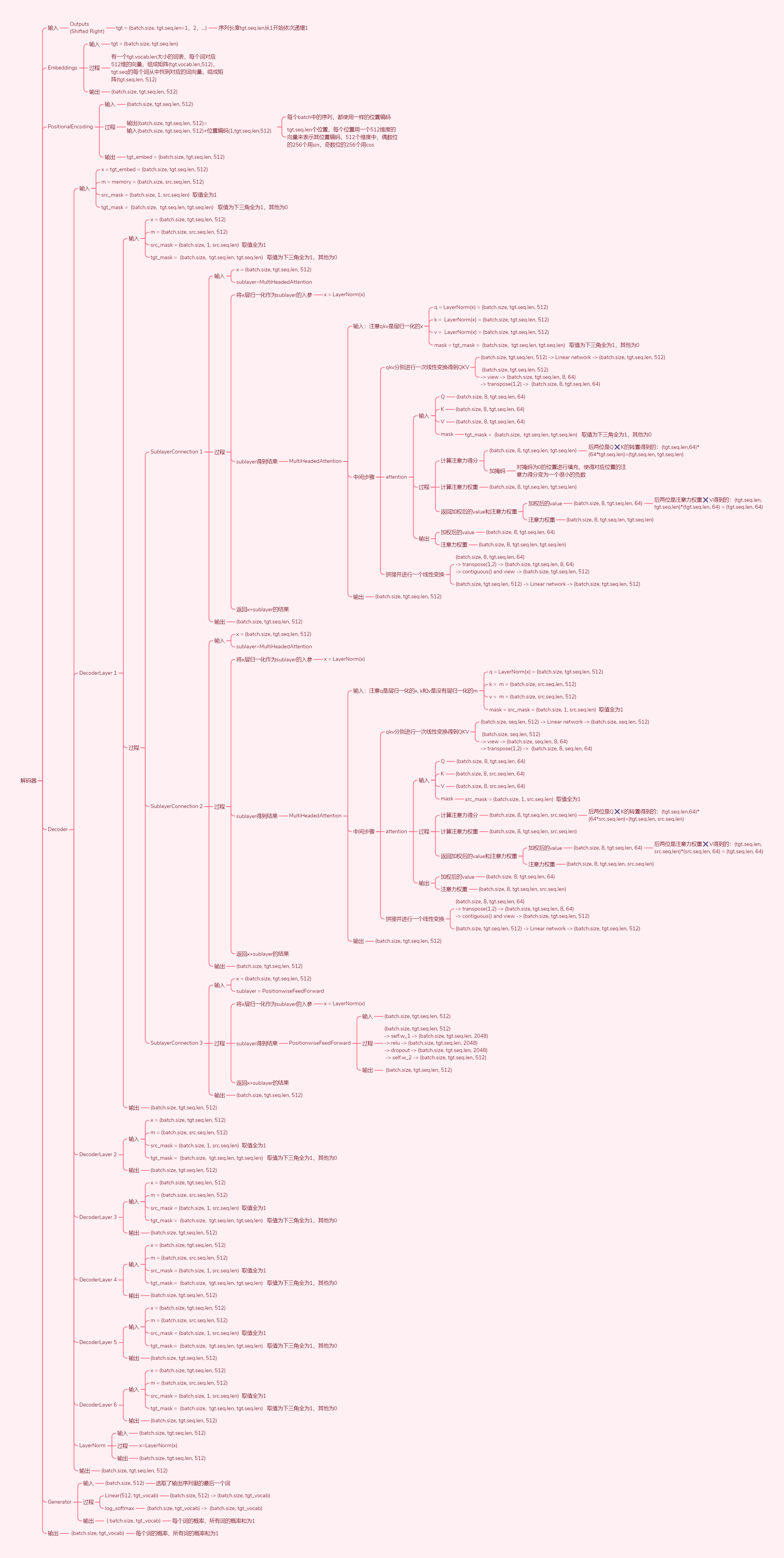
5. 可训练参数量

5.1. MultiHeadedAttention
该块的模型参数:MultiHeadedAttention的4个线性变换的权重和偏置。的权重矩阵和对应偏置,以及输出权重矩阵和对应偏置
该块的参数量大小:4个权重矩阵的形状为, 4个偏置的形状为, MultiHeadedAttention块总的参数量为
该块的个数:编码层有1个子层是MultiHeadedAttention,解码层有2个子层是MultiHeadedAttention,编码器和解码器分别有6个相同的编码层和解码层,所以总共有18个MultiHeadedAttention块
Transformer中该块总的参数量:
5.2. PositionwiseFeedForward
该块的模型参数:PositionwiseFeedForward的2个线性变换的权重和偏置。第一个线性层是先将维度从映射到,第二个线性层再将维度从映射到
该块的参数量大小:第一个线性层的权重矩阵的形状为,偏置的形状为, 第二个线性层的权重矩阵的形状为,偏置的形状为, PositionwiseFeedForward块总的参数量为
该块的个数:编码层和解码层各有1个子层是PositionwiseFeedForward,编码器和解码器分别有6个相同的编码层和解码层,所以总共有12个PositionwiseFeedForward块
Transformer中该块总的参数量:
5.3. LayerNorm
该块的模型参数:LayerNorm包含2个可训练参数:缩放参数和平移参数
该块的参数量大小:两个参数形状都为, LayerNorm块总的参数量为
该块的个数:编码层和解码层的每个子层连接有一个LayerNorm,共有5个子层连接,编码器和解码器分别有6个相同的编码层和解码层,并在6个编码层和解码层后有一个LayerNorm,所以总共有个LayerNorm块
Transformer中该块总的参数量:
5.4. Embeddings
该块的模型参数:该块出现在Transformer中的3个位置(Input Embeddings、Output Embeddings、Generator),但是参数共享,所以只有一份参数
该块的参数量大小:形状为, Embeddings块总的参数量为
该块的个数:1
Transformer中该块总的参数量:
5.5. 总的可训练参数量
6. 源码
6.1. 完整模型
import torch
import torch.nn as nn
import math
from torch.nn.functional import log_softmax
import copy
def make_model(src_vocab, tgt_vocab, N=6, d_model=512, d_ff=2048, h=8, dropout=0.1):
"""
根据超参数构建一个模型。
src_vocab:源句子的单词个数
tgt_vocab:目标句子的单词个数
N:编码层和解码层的层数
d_model:词嵌入的维度/输入和输出的维度
d_ff:Feed-Forward网络中隐藏层的维度/内层的维度
h:注意力的头数
dropout:是一种防止深度学习网络过拟合的技术,它是随机丢弃神经元,从而增加网络的泛化能力
"""
c = copy.deepcopy # 深拷贝
attn = MultiHeadedAttention(h, d_model) # 创建多头注意力机制实例
ff = PositionwiseFeedForward(d_model, d_ff, dropout) # 创建位置前馈网络实例
position = PositionalEncoding(d_model, dropout) # 创建位置编码实例
model = EncoderDecoder(
Encoder(EncoderLayer(d_model, c(attn), c(ff), dropout), N), # 创建编码器实例
Decoder(DecoderLayer(d_model, c(attn), c(attn), c(ff), dropout), N), # 创建解码器实例
nn.Sequential(Embeddings(d_model, src_vocab), c(position)), # 创建源语言嵌入层实例
nn.Sequential(Embeddings(d_model, tgt_vocab), c(position)), # 创建目标语言嵌入层实例
Generator(d_model, tgt_vocab), # 创建生成器实例
)
# 初始化参数
for p in model.parameters():
if p.dim() > 1:
nn.init.xavier_uniform_(p)
return model
6.2. EncoderDecoder(编码器-解码器结构)
class EncoderDecoder(nn.Module):
"""
A standard Encoder-Decoder architecture. Base for this and many other models.
一个标准的编码器-解码器架构。是本例和许多其他模型的基础。
"""
def __init__(self, encoder, decoder, src_embed, tgt_embed, generator):
super(EncoderDecoder, self).__init__()
self.encoder = encoder # 编码器
self.decoder = decoder # 解码器
self.src_embed = src_embed # 源嵌入
self.tgt_embed = tgt_embed # 目标嵌入
self.generator = generator # 生成器
def forward(self, src, tgt, src_mask, tgt_mask):
"Take in and process masked src and target sequences."
"接收并处理 mask 的 源(src) 和 目标(target) 序列。"
return self.decode(self.encode(src, src_mask), src_mask, tgt, tgt_mask)
def encode(self, src, src_mask):
return self.encoder(self.src_embed(src), src_mask) # 对源序列进行编码
def decode(self, memory, src_mask, tgt, tgt_mask):
return self.decoder(self.tgt_embed(tgt), memory, src_mask, tgt_mask) # 对目标序列进行解码
6.3. Encoder(编码器)
class Encoder(nn.Module):
"""Core encoder is a stack of N layers
编码器由N=6个完全相同的层组成。
包含N=6个层的堆叠
"""
def __init__(self, layer, N):
super(Encoder, self).__init__()
self.layers = clones(layer, N) # 创建 N 个 layer 的副本,并存储在 self.layers 中
self.norm = LayerNorm(layer.size) # 创建一个 LayerNorm ,并存储在 self.norm 中
def forward(self, x, mask):
"Pass the input (and mask) through each layer in turn.逐层传递输入和掩码"
for layer in self.layers:
x = layer(x, mask) # 逐层对输入 x 进行处理
return self.norm(x) # 对处理后的结果 x 进行 Layer Normalization(层归一化)
class EncoderLayer(nn.Module):
"Encoder is made up of self-attn and feed forward (defined below) 编码器由自注意力和前馈神经网络组成(如下)。"
def __init__(self, size, self_attn, feed_forward, dropout):
super(EncoderLayer, self).__init__()
self.self_attn = self_attn # 自注意力机制
self.feed_forward = feed_forward # 前馈神经网络
self.sublayer = clones(SublayerConnection(size, dropout), 2) # 克隆两个子层连接
self.size = size
def forward(self, x, mask):
"Follow Figure 1 (left) for connections. 参考图1(左侧)进行连接。"
# 第一个子层连接:自注意力机制
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, mask))
# 第二个子层连接:前馈神经网络
return self.sublayer[1](x, self.feed_forward)
6.4. Decoder(解码器)
解码器也是由 个完全相同的层组成。
除了每个decoder层中的两个子层之外,decoder还有第三个子层,该层对encoder的输出执行multi-head attention。(即encoder-decoder-attention层,q向量来自上一层的输入,k和v向量是encoder最后层的输出向量memory)与encoder类似,我们在每个子层再采用残差连接,然后进行层标准化。
class Decoder(nn.Module):
"""Generic N layer decoder with masking.
通用的 带有掩码(masking)的 N层解码器
包含 N 个层的堆叠
"""
def __init__(self, layer, N):
super(Decoder, self).__init__()
self.layers = clones(layer, N) # 克隆N个解码器层
self.norm = LayerNorm(layer.size) # 归一化层
def forward(self, x, memory, src_mask, tgt_mask):
for layer in self.layers:
# 应用每个解码器层,传递输入x、记忆memory、源掩码src_mask和目标掩码tgt_mask
x = layer(x, memory, src_mask, tgt_mask)
return self.norm(x) # 对输出进行归一化处理
class DecoderLayer(nn.Module):
"Decoder is made of self-attn, src-attn, and feed forward (defined below) 解码器由自注意力机制(self-attn)、源注意力机制(src-attn)和前馈神经网络(feed forward)组成。"
def __init__(self, size, self_attn, src_attn, feed_forward, dropout):
super(DecoderLayer, self).__init__()
self.size = size # 解码器层的大小
self.self_attn = self_attn # 自注意力机制
self.src_attn = src_attn # 源注意力机制
self.feed_forward = feed_forward # 前馈神经网络
self.sublayer = clones(SublayerConnection(size, dropout), 3) # 克隆三个子层连接
def forward(self, x, memory, src_mask, tgt_mask):
"Follow Figure 1 (right) for connections. 参考图1(右侧)进行连接。"
m = memory # 记忆
# 第一个子层连接:自注意力机制
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, tgt_mask))
# 第二个子层连接:源注意力机制
x = self.sublayer[1](x, lambda x: self.src_attn(x, m, m, src_mask))
# 第三个子层连接:前馈神经网络
return self.sublayer[2](x, self.feed_forward)
6.5. MultiHeadedAttention(多头注意力)
为什么使用多头的两点概括:①为了解决模型在对当前位置的信息进行编码时,会过度的将注意力集中于自身位置的问题;②一定程度上h越大整个模型的表达能力越强,越能提高模型对于注意力权重的合理分配。
为什么要缩放:对于较大的来说在完成后将会得到很大的值,而这将导致在经过sofrmax操作后产生非常小的梯度,不利于网络的训练
在实践中,我们同时计算一组query的attention函数,并将它们组合成一个矩阵 . key和value也一起组成矩阵 和 . 。 我们计算的输出矩阵为:
其中Q、K和V分别为3个矩阵,且其(第2个)维度分别为,从后面的计算过程其实可以发现。
def attention(query, key, value, mask=None, dropout=None):
"""缩放的点积注意力
'Scaled Dot Product Attention'
query、key、value和输出都是向量。输出为value的加权和,其中每个value的权重通过query与相应key的兼容函数来计算
"""
d_k = query.size(-1) # 获取查询向量的最后一个维度大小,即注意力的维度
scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k) # 计算注意力得分
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9) # 对掩码为0的位置进行填充,使得对应位置的注意力得分变为一个很小的负数
p_attn = scores.softmax(dim=-1) # 对注意力得分进行softmax归一化,得到注意力权重
if dropout is not None:
p_attn = dropout(p_attn) # 对注意力权重进行dropout操作
return torch.matmul(p_attn, value), p_attn # 返回加权后的value和注意力权重
其中映射由权重矩阵完成: , , and .
在这项工作中,我们采用 个平行attention层或者叫head。对于这些head中的每一个,我们使用 ,将每个head的维度减小,此时总计算成本与具有全部维度的单个head attention相似。
class MultiHeadedAttention(nn.Module):
def __init__(self, h, d_model, dropout=0.1):
super(MultiHeadedAttention, self).__init__()
assert d_model % h == 0
# 我们假设 d_v 总是等于 d_k
self.d_k = d_model // h # 每个头部的注意力维度
self.h = h # 头部的数量
# 定义四个Linear networks, 大小是(512, 512),里面有两类可训练参数,Weights,其大小为512*512,以及biases,其大小为512=d_model
self.linears = clones(nn.Linear(d_model, d_model), 4) # 线性变换层的集合
self.attn = None # 用于存储注意力权重
self.dropout = nn.Dropout(p=dropout)
def forward(self, query, key, value, mask=None):
if mask is not None:
# (batch.size,1,seq.len) -> (batch.size,1,1,seq.len)
mask = mask.unsqueeze(1)
nbatches = query.size(0) # 批次大小
"""
1) 在批次中对所有线性投影进行处理
这里是前三个Linear Networks的具体应用,
例如query=(batch.size, seq.len, 512) -> Linear network -> (batch.size, seq.len, 512)
-> view -> (batch.size, seq.len, 8, 64) -> transpose(1,2) -> (batch.size, 8, seq.len, 64),
其他的key和value也是类似地,从(batch.size, seq.len, 512) -> (batch.size, 8, seq.len, 64)
"""
query, key, value = [lin(x).view(nbatches, -1, self.h, self.d_k).transpose(1, 2) for lin, x in zip(self.linears, (query, key, value))]
# 2) 在批次中对所有投影向量应用注意力机制
x, self.attn = attention(query, key, value, mask=mask, dropout=self.dropout)
"""
3) 使用视图进行"拼接",
x ~ (batch.size, 8, seq.len, 64) -> transpose(1,2) ->
(batch.size, seq.len, 8, 64) -> contiguous() and view ->
(batch.size, seq.len, 8*64) = (batch.size, seq.len, 512)
"""
x = (
x.transpose(1, 2)
.contiguous()
.view(nbatches, -1, self.h * self.d_k)
)
del query
del key
del value
# 4) 然后应用最后一个线性层
# 执行第四个Linear network,把(batch.size, seq.len, 512)经过一次linear network,得到(batch.size, seq.len, 512)
return self.linears[-1](x)
6.6. PositionwiseFeedForward(基于位置的前馈网络)
网络包括两个线性变换,并在两个线性变换中间有一个ReLU激活函数。
尽管两层都是线性变换,但它们在层与层之间使用不同的参数。输入和输出的维度都是 内层维度是 。(也就是第一层输入512维,输出2048维;第二层输入2048维,输出512维)
class PositionwiseFeedForward(nn.Module):
"实现 FFN(Feed-Forward Network)"
def __init__(self, d_model, d_ff, dropout=0.1):
# d_model = 512
# d_ff = 2048 = 512*4
super(PositionwiseFeedForward, self).__init__()
# 构建第一个全连接层,(512, 2048),其中有两种可训练参数:weights矩阵,(512, 2048),以及 biases偏移向量, (2048)
self.w_1 = nn.Linear(d_model, d_ff)
# 构建第二个全连接层, (2048, 512),两种可训练参数:weights矩阵,(2048, 512),以及 biases偏移向量, (512)
self.w_2 = nn.Linear(d_ff, d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
"""
(batch.size, seq.len, 512) -> self.w_1 -> (batch.size, seq.len, 2048)
-> relu -> (batch.size, seq.len, 2048)
-> dropout -> (batch.size, seq.len, 2048)
-> self.w_2 -> (batch.size, seq.len, 512)
"""
return self.w_2(self.dropout(self.w_1(x).relu()))
6.7. Embeddings(嵌入层)
将输入token和输出token转换为 维的向量
class Embeddings(nn.Module):
def __init__(self, d_model, vocab):
super(Embeddings, self).__init__()
# (vocab.len, 512)
self.lut = nn.Embedding(vocab, d_model)
self.d_model = d_model
def forward(self, x):
# (batch.size, seq.len) -> (batch.size, seq.len, 512)
return self.lut(x) * math.sqrt(self.d_model)
6.8. PositionalEncoding(位置编码)
由于我们的模型不包含循环和卷积,为了让模型利用序列的顺序,我们必须加入一些序列中token的相对或者绝对位置的信息。为此,我们将“位置编码”添加到编码器和解码器堆栈底部的输入embeddinng中。位置编码和embedding的维度相同,也是 , 所以这两个向量可以相加。
使用不同频率的正弦和余弦函数:
其中 是位置, 是维度。也就是说,位置编码的每个维度对应于一个正弦曲线。 这些波长形成一个从 到 . 的集合级数。 我们选择这个函数是因为我们假设它会让模型很容易学习对相对位置的关注,因为对任意确定的偏移 , 可以表示为 的线性函数。
此外,我们会将编码器和解码器堆栈中的embedding和位置编码的和再加一个dropout。对于基本模型,我们使用的dropout比例是 .
它使用指数函数来生成一系列按位置缩放的值。这些值后续将用于计算正弦和余弦位置编码。让我们逐步解析这段代码: torch.arange(0, d_model, 2): 创建一个从0开始到d_model(不包括)的一维张量,步长为2。 d_model通常是Transformer模型中的一个参数,表示编码的尺寸或“深度”。这一步生成的序列用于计算每个维度的位置编码的频率。 * -(math.log(10000.0) / d_model): math.log(10000.0)计算10000的自然对数。 这个值之后被除以d_model以获得一个缩放因子,然后乘上前面torch.arange生成的序列的每个元素。 由于有一个负号,这意味着符号的翻转。此计算实现了Transformer中位置编码的一个关键部分:随着维度的增加,每个位置的频率按对数级别减少。 torch.exp(...): 对上一步计算的结果应用指数函数。由于输入的每个元素都是负值(因为前面有负号),这会产生一系列在0到1之间递减的值。 这些值在计算正弦和余弦函数时提供了不同的波长,这是Transformer模型中利用位置信息的一种方式。 转换为简单的话来说,这段代码通过在不同频率上为每个位置生成不同的缩放因子,来为Transformer模型中的每个位置编码生成一个序列。 这种基于位置的编码帮助模型理解单词或标记之间的相对或绝对位置关系,这是自然语言处理(NLP)中的一个重要概念。 位置编码与输入嵌入相加后,就可以提供给模型输入的完整表示,包含了单词的语义信息及其在序列中的位置信息。
class PositionalEncoding(nn.Module):
def __init__(self, d_model, dropout, max_len=5000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
# 事先准备好max_len=5000的序列的位置编码
# (5000,512)矩阵,一共5000个位置,每个位置用一个512维度向量来表示其位置编码
pe = torch.zeros(max_len, d_model)
# (5000)->(5000,1)
position = torch.arange(0, max_len).unsqueeze(1)
# (256)
div_term = torch.exp(torch.arange(0, d_model, 2) * -(math.log(10000.0) / d_model))
# 偶数下标的位置,(5000,256)
pe[:, 0::2] = torch.sin(position * div_term)
# 奇数下标的位置,(5000,256)
pe[:, 1::2] = torch.cos(position * div_term)
# (5000, 512) -> (1, 5000, 512) 为batch.size留出位置
pe = pe.unsqueeze(0)
self.register_buffer("pe", pe)
def forward(self, x):
"""
:param x: Embeddings的词嵌入结果
:return: Embeddings结果+位置编码结果
注意,位置编码不会更新,是写死的,所以这个class里面没有可训练的参数
x.size(1)是src.seq.len, 从准备好的5000位置中截取序列长度的大小
在具体相加的时候,会扩展(1,src.seq.len,512)为(batch.size,src.seq.len,512)
每个batch中的序列,都使用一样的位置编码
"""
x = x + self.pe[:, : x.size(1)].requires_grad_(False)
return self.dropout(x)
6.9. Generator(生成器)
class Generator(nn.Module):
"""Define standard linear + softmax generation step."
"定义标准的 linear + softmax 生成步骤。
使用普通的线性变换和softmax函数将解码器输出转换为预测的下一个token的概率
"""
def __init__(self, d_model, vocab):
super(Generator, self).__init__()
self.proj = nn.Linear(d_model, vocab) # 线性投影层,将输入维度转换为词汇表(vocab)大小
def forward(self, x):
return log_softmax(self.proj(x), dim=-1) # 对线性投影结果应用log_softmax函数,进行归一化和概率计算
log_softmax函数就是对softmax函数的每个元素求对数操作,也是为了概率归一化的操作,常用于神经网络中,尤其是注意力机制中概率得分的计算。由于 softmax 得到的概率分布和 log_softmax 得到的概率分布可以相加减,因此将原始分数转换为对数形式可以避免溢出,并且更容易计算概率乘法。LogSoftmax相对于Softmax的优势在于对数运算时求导更容易,加快了反向传播的速度。解决Softmax可能存在的上溢和下溢的问题。
6.10. clones(克隆)
def clones(module, N):
"Produce N identical layers."
"复制n个相同的层"
return nn.ModuleList([copy.deepcopy(module) for _ in range(N)])
6.11. LayerNorm(层归一化)
这段代码实现了一个简单的 Layer Normalization 模块:在 init 方法中,它接受一个整数 features 和一个小的常数 eps (eps=1e-6)作为参数。它首先调用 nn.Module 的构造函数来初始化父类。然后,它创建了两个可学习的参数 a_2 和 b_2,分别用于缩放和平移操作。这些参数的形状为 (features,),其中 features 是输入张量的最后一个维度的大小。最后,它将 eps 存储在实例变量 self.eps 中。在 forward 方法中,它接受输入张量 x 作为参数。它首先计算 x 在最后一个维度上的均值 mean 和标准差 std。然后,它使用这些统计量对 x 进行 Layer Normalization,即将 x 减去均值并除以标准差。最后,它将缩放参数 a_2 乘以归一化后的结果,并加上平移参数 b_2,得到最终的输出。
class LayerNorm(nn.Module):
"Construct a layernorm module (See citation for details)."
def __init__(self, features, eps=1e-6): # features是一个整数
super(LayerNorm, self).__init__()
self.a_2 = nn.Parameter(torch.ones(features))
self.b_2 = nn.Parameter(torch.zeros(features))
self.eps = eps
def forward(self, x):
mean = x.mean(-1, keepdim=True)
std = x.std(-1, keepdim=True)
return self.a_2 * (x - mean) / (std + self.eps) + self.b_2
6.12. SublayerConnection(子层连接)
每个子层的输出是 , 其中 是子层本身实现的函数。我们将 dropout(Dropout: A Simple Way to Prevent Neural Networks from Overfitting,The key idea is to randomly drop units (along with their connections) from the neural network during training.) 应用于每个子层的输出,然后再将其添加到子层输入中并进行归一化。 为了便于进行残差连接(residual connections),模型中的所有子层以及embedding层产生的输出的维度都为.
在残差连接中,输入通过一个跨层连接(shortcut connection)直接添加到层的dropout后的输出上(x + self.dropout(sublayer(self.norm(x))))。为了保持维度一致性,可以在残差连接中应用 Layer Normalization。这样可以确保残差连接中的输入和输出都经过了相同的归一化处理,从而提高网络的训练效果和性能。
class SublayerConnection(nn.Module):
"""
A residual connection followed by a layer norm.
Note for code simplicity the norm is first as opposed to last.
一个残差连接(residual connection)后跟一个层归一化(LayerNorm)
为了代码的简洁性,将层归一化放在残差连接之前
"""
def __init__(self, size, dropout):
# size=d_model=512; dropout=0.1
super(SublayerConnection, self).__init__()
self.norm = LayerNorm(size)
self.dropout = nn.Dropout(dropout)
def forward(self, x, sublayer):
"""
Apply residual connection to any sublayer with the same size.
应用残差连接和层归一化,返回最终的输出,将残差连接应用于具有相同大小的任何子层。
x (batch.size, seq.len, 512)
sublayer 是一个具体的 MultiHeadAttention 或者 Position-wise FeedForward 对象的结果
x (batch.size, seq.len, 512) -> norm (LayerNorm) -> (batch.size, seq.len, 512)
-> sublayer (MultiHeadAttention or PositionwiseFeedForward, 子层传入的x是层归一化后的x)
-> (batch.size, seq.len, 512) -> dropout -> (batch.size, seq.len, 512)
然后输入的x(没有走sublayer) + 上面的结果,即实现了残差相加的功能
"""
return x + self.dropout(sublayer(self.norm(x)))
6.13. 模型使用的例子
if __name__ == '__main__':
flag = 0
if flag == 0:
# 假设英语词汇表大小为10000,中文词汇表大小为15000
src_vocab_size = 10000
tgt_vocab_size = 15000
src = torch.LongTensor([[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]]) # 创建输入序列张量
src_mask = torch.ones(1, 1, 10) # 创建输入序列的掩码张量
ys = torch.zeros(1, 1).type_as(src) # 创建初始输出序列张量
print(ys)
test_model = make_model(src_vocab_size, tgt_vocab_size) # 创建一个模型实例
test_model.eval() # 将模型设置为评估模式
memory = test_model.encode(src, src_mask) # 编码输入序列,得到记忆张量
print(f'src:{src.shape}')
print(f'memory:{memory.shape}')
for i in range(8):
print(f'ys:{ys.shape}')
print(ys)
t = subsequent_mask(ys.size(1)).type_as(src.data)
out = test_model.decode(
memory, src_mask, ys, subsequent_mask(ys.size(1)).type_as(src.data)
) # 解码输出序列
t = out[:, -1]
print(f'out:{out.shape},generator的入参:{t.shape}')
prob = test_model.generator(out[:, -1]) # 通过生成器获得下一个词的概率分布
_, next_word = torch.max(prob, dim=1) # 选择概率最高的下一个词
print("最高概率的下一个词:", next_word.item()) # 打印最高概率的下一个词的索引
next_word = next_word.item() # 获取下一个词的索引
ys = torch.cat(
[ys, torch.empty(1, 1).type_as(src.data).fill_(next_word)], dim=1
) # 将下一个词添加到输出序列中
print("未经训练的预测结果:", ys)
elif flag == 1:
V = 11
batch_size = 80
data_iter = data_gen(V, batch_size, 20)
model = make_model(V, V)
for i, batch in enumerate(data_iter):
# 使用模型进行前向传播
out = model.forward(
batch.src, batch.tgt, batch.src_mask, batch.tgt_mask
)
if i == 0:
print(out.shape)
print(out)
def subsequent_mask(size):
"""
Mask out subsequent positions.
屏蔽后续位置的注意力
在训练时将当前单词的未来信息屏蔽掉,阻止此单词关注到后面的单词。
防止在当前位置关注到后面的位置。这种掩码结合将输出embedding偏移一个位置,确保对位置i的预测只依赖位置i之前的已知输出。
"""
# 注意力矩阵的形状
attn_shape = (1, size, size)
# 创建上三角矩阵
subsequent_mask = torch.triu(torch.ones(attn_shape), diagonal=1).type(
torch.uint8
)
return subsequent_mask == 0
class Batch:
"""
批处理和掩码
用于在训练过程中保存一个数据批次及其掩码的对象。
"""
def __init__(self, src, tgt=None, pad=2): # 2 = <blank>,用于指定填充标记的索引
# src: 源语言序列,(batch.size, src.seq.len)
# 二维tensor,第一维度是batch.size;第二个维度是源语言句子的长度
# 例如:[ [2,1,3,4], [2,3,1,4] ]这样的二行四列的,
# 1-4代表每个单词word的id
# tgt: 目标语言序列,默认为空,其shape和src类似
# (batch.size, tgt.seq.len),
# 二维tensor,第一维度是batch.size;第二个维度是目标语言句子的长度
# 例如tgt=[ [2,1,3,4], [2,3,1,4] ] for a "copy network"
# (输出序列和输入序列完全相同)
# pad: 源语言和目标语言统一使用的 位置填充符号,'<blank>'
# 所对应的id,这里默认为0
# 例如,如果一个source sequence,长度不到4,则在右边补0
# [1,2] -> [1,2,0,0]
self.src = src # 源序列张量
# 在注意力机制的计算中,这个掩码可以用来确保模型不会考虑到填充位置的元素,
# 即通过让填充位置的注意力权重接近于零或实际上为零。
# 这样处理,模型就只会在非填充的元素上计算注意力,从而避免填充值干扰模型理解和处理序列的能力。
self.src_mask = (src != pad).unsqueeze(-2) # 源序列的掩码张量,用于遮盖填充位置
# src = (batch.size, seq.len) -> != pad ->
# (batch.size, seq.len) -> usnqueeze ->
# (batch.size, 1, seq.len) 相当于在倒数第二个维度扩展
# e.g., src=[ [2,1,3,4], [2,3,1,4] ]对应的是
# src_mask=[ [[1,1,1,1], [1,1,1,1]] ]
if tgt is not None:
self.tgt = tgt[:, :-1] # 目标序列张量,去除最后一个位置的标记
# tgt 相当于目标序列的前N-1个单词的序列
#(去掉了最后一个词)
self.tgt_y = tgt[:, 1:] # 目标序列张量的下一个位置的标记
# tgt_y 相当于目标序列的后N-1个单词的序列
# (去掉了第一个词)
# 目的是(src + tgt) 来预测出来(tgt_y),
self.tgt_mask = self.make_std_mask(self.tgt, pad) # 目标序列的掩码张量,用于遮盖填充位置和未来位置
self.ntokens = (self.tgt_y != pad).data.sum() # 目标序列中非填充标记的数量
@staticmethod
def make_std_mask(tgt, pad):
"创建一个掩码,用于隐藏填充位置和未来的词。"
# 这里的tgt类似于:
#[ [2,1,3], [2,3,1] ] (最初的输入目标序列,分别去掉了最后一个词
# pad=0, '<blank>'的id编号
tgt_mask = (tgt != pad).unsqueeze(-2) # 创建一个掩码张量,用于遮盖填充位置
# 得到的tgt_mask类似于
# tgt_mask = tensor([[[1, 1, 1]],[[1, 1, 1]]], dtype=torch.uint8)
# shape=(2,1,3)
tgt_mask = tgt_mask & subsequent_mask(tgt.size(-1)).type_as(
tgt_mask.data
) # 与一个用于遮盖未来位置的掩码张量相与,以得到最终的目标序列掩码张量
# 先看subsequent_mask, 其输入的是tgt.size(-1)=3
# 这个函数的输出为= tensor([[[1, 0, 0],
# [1, 1, 0],
# [1, 1, 1]]], dtype=torch.uint8)
# type_as 把这个tensor转成tgt_mask.data的type(也是torch.uint8)
# 这样的话,&的两边的tensor形状分别是(2,1,3) & (1,3,3) 进行与操作之后得到形状(2,3,3)的结果
#tgt_mask = tensor([[[1, 1, 1]],[[1, 1, 1]]], dtype=torch.uint8)
#and
# tensor([[[1, 0, 0], [1, 1, 0], [1, 1, 1]]], dtype=torch.uint8)
# 形状(2,3,3)就是得到的tensor
# tgt_mask.data = tensor([[[1, 0, 0],
# [1, 1, 0],
# [1, 1, 1]],
#[[1, 0, 0],
# [1, 1, 0],
# [1, 1, 1]]], dtype=torch.uint8)
return tgt_mask
def data_gen(V, batch_size, nbatches):
"Generate random data for a src-tgt copy task. 合成数据"
"""
尝试一个简单的复制任务开始。给定来自小词汇表的一组随机输入符号symbols,目标是生成这些相同的符号
"""
for i in range(nbatches):
data = torch.randint(1, V, size=(batch_size, 10))
data[:, 0] = 1
src = data.requires_grad_(False).clone().detach()
tgt = data.requires_grad_(False).clone().detach()
yield Batch(src, tgt, 0)